1 Wprowadzenie
1.1 Prognozowanie zapotrzebowania na energię elektryczną
Prognozowanie obciążenia energią elektryczną pozostaje jednym z podstawowych problemów biznesowych, z jakimi boryka się sektor elektroenergetyczny. W szczególności, dokładne prognozy są niezbędnym elementem procesu przygotowywania kontraktów pomiędzy dostawcami i odbiorcami energii elektrycznej. W przypadku dostarczenia mocy niższej od zapotrzebowania, dostawca ponosi stratę (np. płaci karę). Z drugiej strony, dodatkowe koszty mogą pojawiają się również gdy dostarczona moc jest wyższa niż rzeczywiste zapotrzebowanie (np. koszty sprzedaży energii na rynku SPOT / bilansującym). Dokładne prognozy są metodą obniżania kosztów ponoszonych przez dostawców energii elektrycznej.
Oczywiście istnieje wiele rodzajów kontraktów energetycznych. Niektóre z nich przewidują kary tylko wtedy, gdy dostarczona moc spadnie poniżej zakontraktowanej wartości. Inne przenoszą całe ryzyko na klientów i zobowiązują ich do zakupu dodatkowej energii na rynku bilansującym lub SPOT. Różne rodzaje kontraktów niewątpliwie wymagają różnych schematów oceny prognoz.
Dobór odpowiednich modeli prognostycznych uwzględniających specyfikę zapotrzebowania na energię elektryczną jest wymagającym zadaniem. Po pierwsze, struktury zapotrzebowania mogą się znacząco różnić. Podczas gdy niektóre z nich wykazują silną i zazwyczaj złożoną sezonowość, inne mogą mogą mieć znacznie bardziej zróżnicowaną strukturę (np. bez znaczących wahań sezonowych). Po drugie, różni klienci mogą mierzyć zapotrzebowania na energię w różnych odcinkach czasu (w szczególności nie wszyscy klienci rejestrują zapotrzebowanie godzinowe). Ponadto, istnieje szereg czynników egzogenicznych (np. czynniki związane z warunkami pogodowymi itp.), które mogą znacząco wpłynąć na rzeczywiste zużycie energii.
1.2 Zadanie
Z punktu widzenia dostawcy energii, głównym zadaniem jest konstruowanie dokładnych prognoz dobowego lub godzinowego zapotrzebowania na energię elektryczną, zazwyczaj dla znacznej liczby zróżnicowanych przebiegów zapotrzebowania. Niestety, w praktyce często stosowane są słabe modele prognostyczne, które mogą prowadzić do zawyżania lub zaniżania prognoz. Dodatkowo, stosowane oprogramowanie często nie jest stabilne. W związku z tym istnieje duże zapotrzebowanie na efektywne i przejrzyste narzędzia, które byłyby w stanie wykonywać prognozy obciążenia energetycznego dla klientów o różnych potrzebach.
1.3 Rozwiązanie
W celu zapewnienia dokładnych prognoz obciążenia energią elektryczną należy opracować odpowiednie podejście, uwzględniające wszystkie specyficzne okoliczności. Oczywiście w pierwszej kolejności należy wziąć pod uwagę historyczne dane dotyczące zapotrzebowania na energię, jak również aktualne informacje dotyczące istotnych czynników zewnętrznych. Przy budowie systemu prognostycznego równie ważne jest zadbanie o archiwizację i walidację wyników, które pozwolą dostawcom na weryfikację jakości uzyskiwanych prognoz. W konsekwencji można spodziewać się zmniejszenia kosztów związanych z niedokładnym oszacowaniem zapotrzebowania na energię.
2 Dane
2.1 Dane
W analizie wykorzystano zbiór danych dotyczących obciążenia Krajowego Systemu Energetycznego (KSE). Oryginalne dane, składające się z 15-minutowych wartości chwilowych (w MW), zostały pobrane ze strony internetowej Polskich Sieci Elektroenergetycznych S.A. (https://www.pse.pl/home), a następnie zagregowane do wartości godzinowych. Ostatecznie uzyskaliśmy ponad 120 000 obserwacji zawierających godzinowe wartości zapotrzebowania na moc pochodzących z okresu trzynastu lat.
Nasz zbiór danych został przedstawiony na rysunku 1 (dla przejrzystości przedstawiono dane z wybranego odcinka czasu). Łatwo zauważyć, że dane wykazują wiele sezonowości, tzn. można zidentyfikować dzienne, tygodniowe i roczne wzorce sezonowe. Dodatkowo można zaobserwować, że zmiany wolumenu w okresach świątecznych.
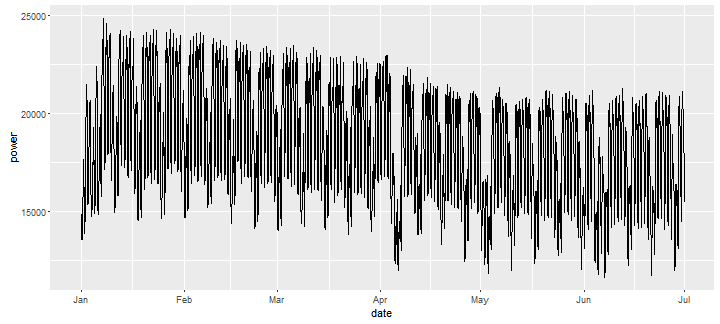 Rysunek 1. Dane godzinowe zawierające obciążenie Polskiego Systemu Elektroenergetycznego w wybranym okresie czasu.
Rysunek 1. Dane godzinowe zawierające obciążenie Polskiego Systemu Elektroenergetycznego w wybranym okresie czasu.
2.2 Dane - czynniki
W analizie uwzględniono również czynniki zewnętrzne (egzogeniczne) związane z warunkami atmosferycznymi. Obejmowały one dane godzinowe o temperaturze, zachmurzeniu i prędkości wiatru (składowe współczynnika chłodu) z 82 stacji z terenu całej Polski. Do analiz wykorzystano uśrednione dla całego kraju dane meteorologiczne.
Na rysunku 2 przedstawiono uwzględnione w procesie modelowania warunki meteorologiczne rejestrowane dla kolejnych punktów czasowych. Oczywiście można się spodziewać, że wykorzystanie tych dodatkowych informacji może poprawić dokładność prognozowania zapotrzebowania na energię.
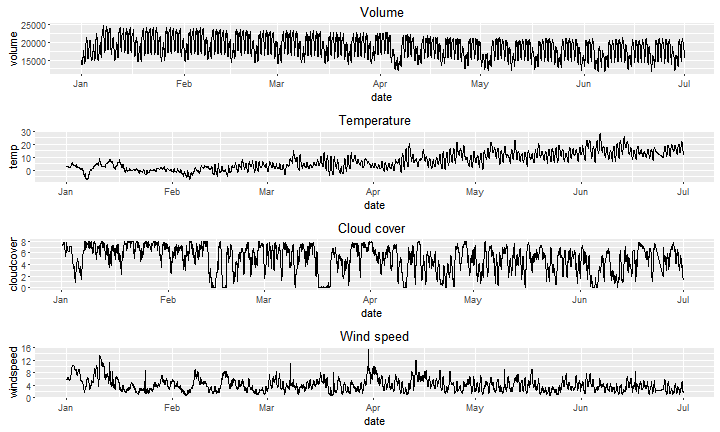 Rysunek 2. Dzienne obciążenie energetyczne (rysunek górny) oraz trzy czynniki zewnętrzne (związane z warunkami pogodowymi), które mogą wpływać na zużycie energii.
Rysunek 2. Dzienne obciążenie energetyczne (rysunek górny) oraz trzy czynniki zewnętrzne (związane z warunkami pogodowymi), które mogą wpływać na zużycie energii.
3 Analiza
3.1 Trzy podejścia / frameworki
Jak już wspomniano, do budowy modeli prognostycznych wykorzystaliśmy trzy różne podejścia, zaproponowane przez trzech data scientistów (współautorów niniejszego raportu, tj. Artura Suchwałko, Tomasza Melcera, Adama Zagdańskiego) o różnym doświadczeniu. Obejmowały one:
- modelowanie oparte na regresji,
- modele szeregów czasowych,
- głębokie sieci neuronowe.
Wszystkie wymienione podejścia zostały szczegółowo opisane w kolejnych rozdziałach. W tym miejscu należy jedynie wspomnieć, że w każdym z podejściu testowano różne kryteria wyboru modeli, bazujące zarówno na eksperckiej wiedzy jak i charakterystyce badanego zbioru danych. Co istotne, zakładamy, że prognoza czynników egzogenicznych jest doskonała. Oznacza to, że do analizy błędu prognozy nie wliczamy niepewności prognozowania czynników pogodowych. Ponadto, w celu porównania dokładności prognoz wszystkich rozpatrywanych w artykule procedur, zastosowano podział danych na zbiór uczący i testowy.
3.2 Inne zastosowania
Warto zaznaczyć, że metody przedstawione w niniejszym opracowaniu są dość ogólne, a ich możliwe zastosowania nie ograniczają się do prognozowania zapotrzebowania na energię. W szczególności, opisane metody mogą być przydatne w prognozowaniu innych zjawisk lub wielkości, gdzie występują czynniki zewnętrzne (egzogeniczne) lub złożone wzorce sezonowości.
3.3 Regresja
3.3.1 Idea
Analiza regresji jest procesem szacowania zależności pomiędzy zmiennymi. Podstawowym celem regresji jest opisanie (prognozowanie) wartości zmiennej (zwanej zależną) na podstawie wartości szeregu innych zmiennych (zwanych niezależnymi).
Zależność tę można opisać za pomocą różnych podejść, od bardzo prostych funkcji liniowych (tzw. regresja liniowa) do dużych modeli nieparametrycznych (np. procesy gaussowskie, sieci neuronowe). Metody te mogą wywodzić się zarówno z klasycznej statystyki/teorii prawdopodobieństwa, obejmującej matematyczne metody modelowania, jak i uczenia maszynowego, bardziej skoncentrowanego na mocy predykcyjnej. Wybór zależy od wielu czynników. Jednym z najważniejszych czynników jest rozmiar zbioru danych. Złożone metody, o wielu stopniach swobody, wymagają użycia dużych zbiorów danych (użycie zbioru danych o niedostatecznym rozmiarze prowadzi do przeuczenia modelu). Złożone metody zazwyczaj są również trudne do zinterpretowania, podczas gdy prostsze metody, z małą liczbą parametrów są łatwiejsze do zrozumienia. Użycie złożonych metod predykcyjnych często przekłada się na uzyskanie dokładniejszych prognoz. Niektóre inne czynniki, które wpływają na wybór metody regresji to charakterystyczne dla danej dziedziny praktyki (zestaw metod dobrze znanych w danej społeczności), odporność na anomalie i naruszenia założeń modelu, dostępność określonych miar błędu (czy łatwo jest użyć nietypowych kryteriów w procesie optymalizacji modelu) oraz koszty obliczeniowe (niektóre metody wymagają dużych nakładów czasowych lub dedykowanego sprzętu, aby uzyskać dobre wyniki).
Nie istnieje metoda gwarantująca najlepsze rezultaty w każdym przypadku. Możliwe jest porównanie mocy predykcyjnej różnych podejść dla konkretnego zbioru danych przy użyciu różnych technik wyboru modelu i walidacji, ale wyniki będą różne dla różnych klas zbiorów danych. Ponadto, dla badacza inne czynniki mogą być ważniejsze niż tylko posiadanie dokładnych prognoz: na przykład, interpretowalny model może prowadzić do wglądu w modelowany proces, a niski narzut obliczeniowy może być istotny dla prognoz krótkoterminowych.
Przegląd klasycznych i nowoczesnych metod regresji można znaleźć np. w Hastie, Tibshirani i Friedman (2009).
3.3.2 Co wybraliśmy?
Po kilku wstępnych testach zdecydowaliśmy się na wykorzystanie klasycznej metody SVM (Support Vector Machine). Jako zmienne niezależne zostały użyte wolumen i inne czynniki z momentu teraźniejszego i przeszłego oraz zmienne opisujące sezonowość zakodowane jako zmienne dummy (binarne zmienne kodujące występowanie danego stanu zmiennej). Zmienną zależną był wolumen z momentu przyszłego.
3.3.3 Prognozowanie z wykorzystaniem regresji
Rysunek 3 ilustruje regresyjne podejście do prognozowania. Przedstawia on przeszłe wartości czynników (oznaczane przez F(⋅) ) z chwil t-h do t+1 (wartości przyszłe traktowane są jako znane, nie prognozowane) oraz przeszłe wartości wolumenu oznaczane przez V(⋅) z chwil t-h do t . Wartości te tworzą wektor zmiennych niezależnych. Zmienną niezależną jest wartość wolumenu z chwili t+1 . Funkcja regresji oznaczana jest przez f(⋅) .
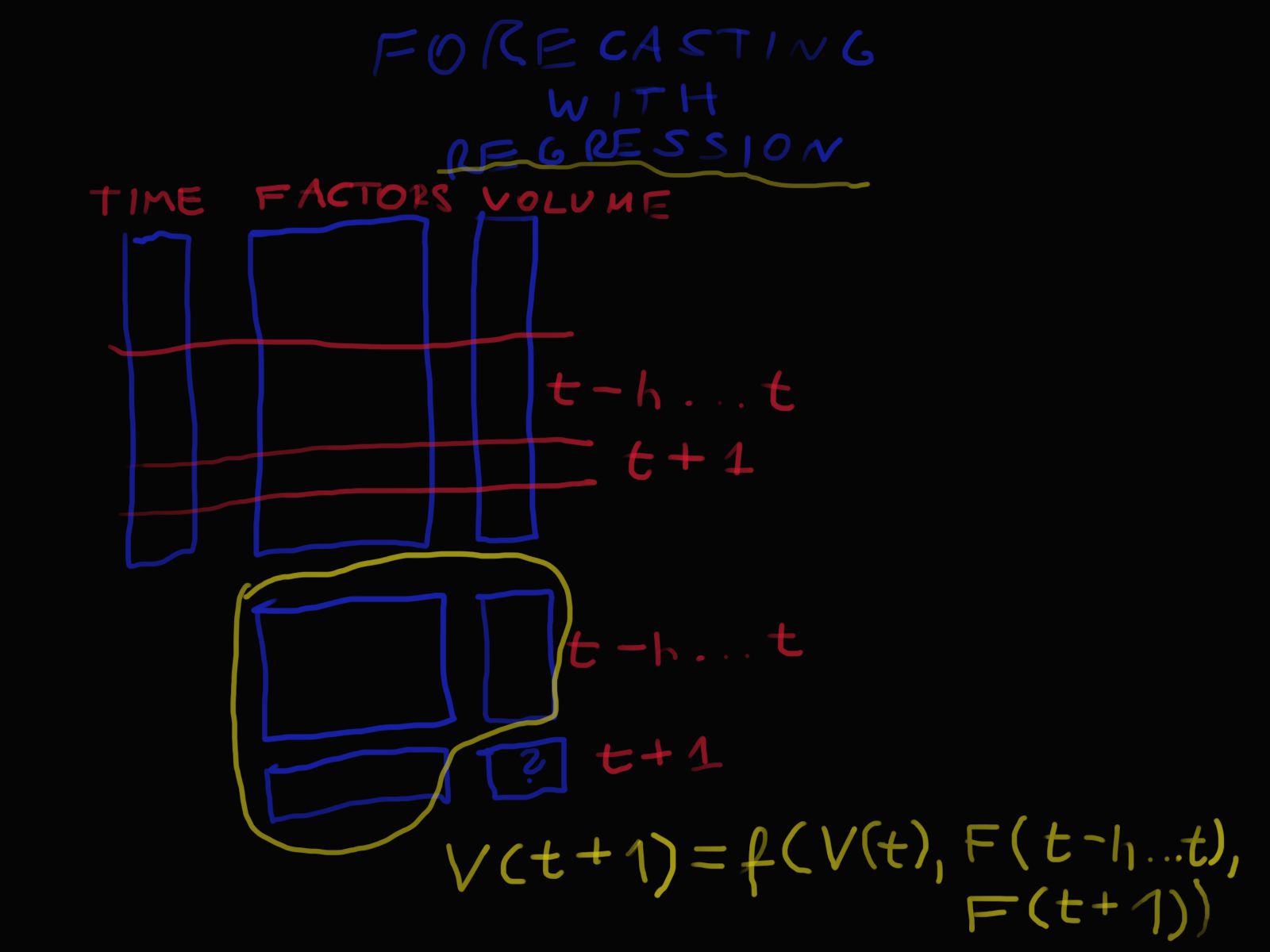 Rysunek 3. Prognozowanie za pomocą regresji.
Rysunek 3. Prognozowanie za pomocą regresji.
3.3.4 Kodowanie zmiennych
Rysunek 4 przedstawia kodowanie zmiennych czynnikowych, takich jak dzień tygodnia czy miesiąc kalendarzowy. Jest to klasyczne podejście, w którym zmienna mająca n poziomów jest reprezentowana przez n-1 zmiennych binarnych kodujących występowanie danej wartości zmiennej. Zmienne uzyskane poprzez takie przekształcenie nazywamy zmiennymi dummy.
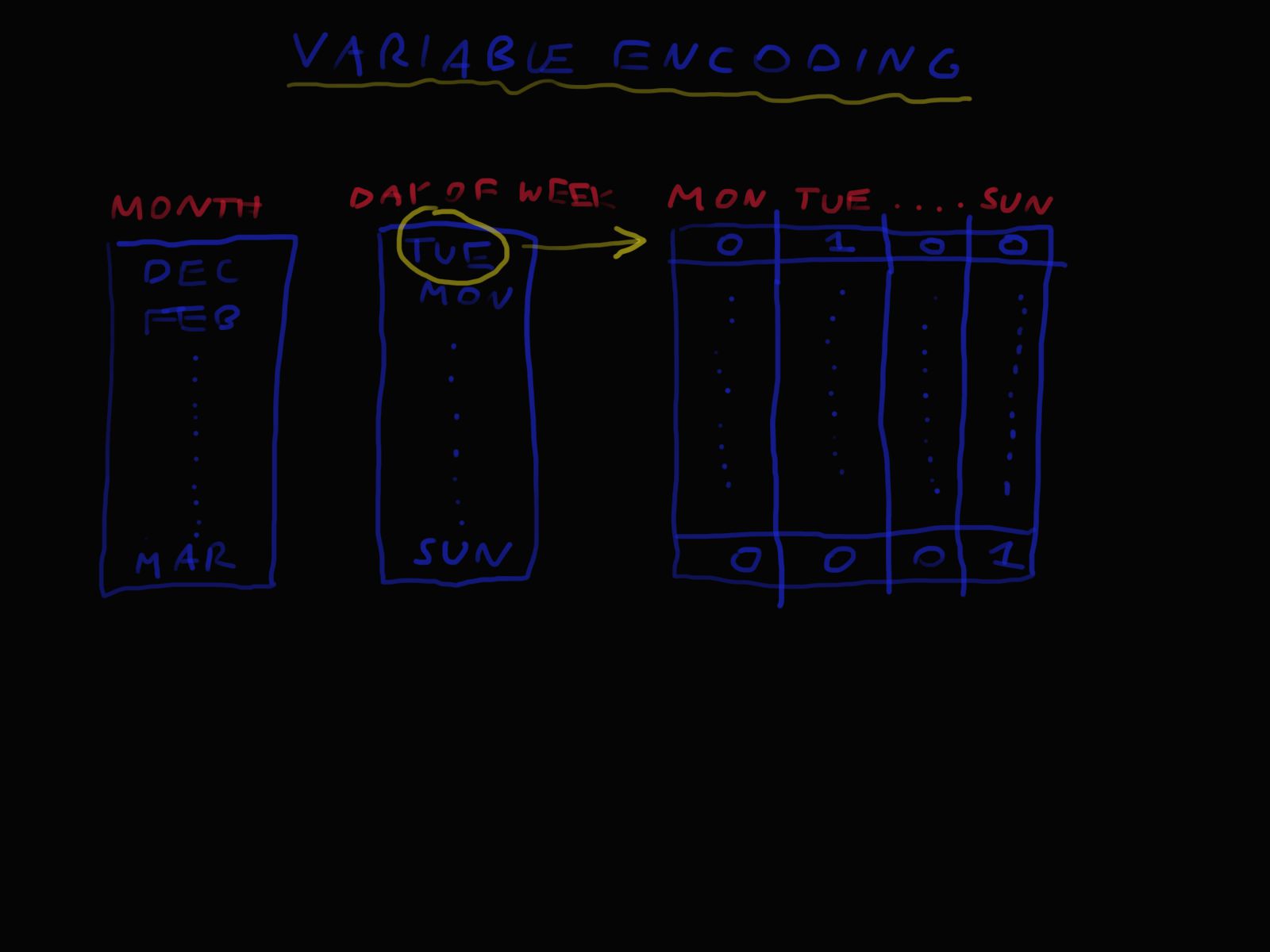 Rysunek 4. Idea kodowania zmiennych w modelu regresji.
Rysunek 4. Idea kodowania zmiennych w modelu regresji.
3.3.5 Walidacja krzyżowa
Standardowa walidacja krzyżowa polega na podziale danych na pewną liczbę podzbiorów (ang. folds), a następnie uczeniu i testowaniu modelu z wykorzystaniem każdego z podzbiorów jako zbioru testowego i pozostałych jako uczącego.
Podejście z losowym podziałem na podzbiory nie jest adekwatne do niniejszej analizy, ponieważ zależy nam, żeby zbiór testowy zawsze leżał po zbiorze uczącym na osi czasu (czego nie gwarantuje ta metoda). Jest to ważne dla symulacji testowania modeli prognozowania szeregów czasowych w warunkach rzeczywistych. W takiej sytuacji zazwyczaj model jest budowany na zbiorze danych z pewnego okresu czasu i testowany na danych z kolejnego okresu czasu.
Rysunek 5 przedstawia podejście do walidacji krzyżowej specyficznej dla danych zależnych od czasu.
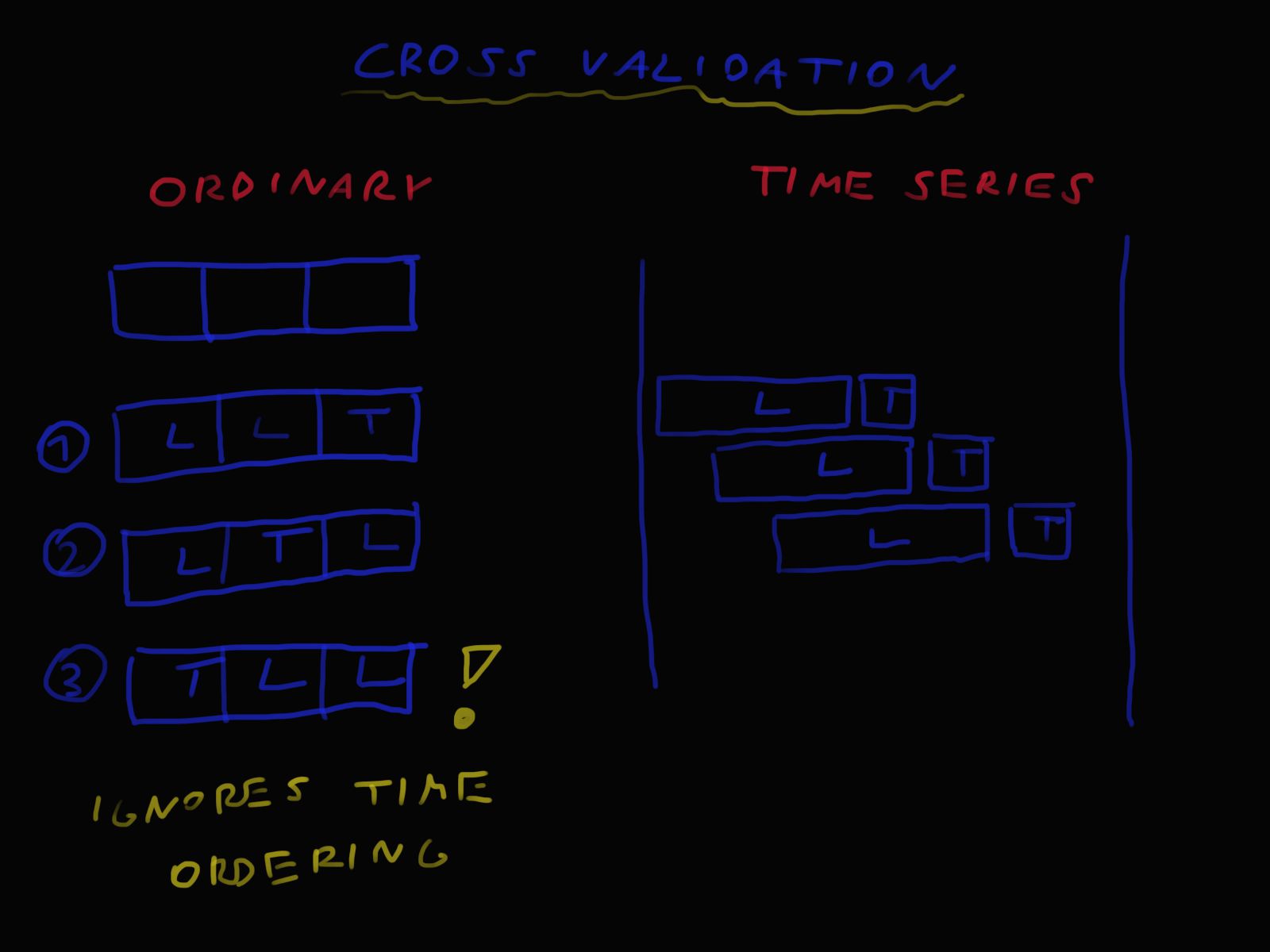 Rysunek 5. Idea schematu walidacji krzyżowej.
Rysunek 5. Idea schematu walidacji krzyżowej.
3.4 Modele szeregów czasowych
3.4.1 Idea
Modele bazujące na szeregach czasowych zostały opracowane w celu bezpośredniego uwzględnienia określonej struktury zależnej od czasu w analizowanych danych. Modele dla danych szeregów czasowych mogą mieć wiele form (patrz np. Hyndman i Athanasopoulos (2013) czy Zagdański i Suchwałko (2015)). Należą do nich m.in. dobrze znane modele ARMA, ARIMA, GARCH i inne klasy modeli, których własności zostały dokładnie zbadane w obszernej literaturze. Oczywiście, dysponujemy metodami umożliwiającymi modelowanie z uwzględnieniem złożonych wzorców sezonowości.
Modele szeregów czasowych są prostymi i stabilnymi modelami matematycznymi, posiadają solidne podstawy teoretyczne. Modele takie są zazwyczaj łatwe w interpretacji. Co więcej, oprócz punktowych wartości prognoz, można skonstruować przedziały predykcji, aby wskazać prawdopodobną niepewność w prognozach punktowych. Z drugiej strony, do znalezienia optymalnego modelu często potrzebna jest wiedza ekspercka i odpowiednie doświadczenie. Innym ograniczeniem jest stosunkowo mała elastyczność, np. większość popularnych klas modeli szeregów czasowych opiera się na założeniu liniowej zależności, co może nie być ani adekwatne, ani optymalne w przypadku niektórych zastosowań.
3.4.2 Co wybraliśmy?
W naszej analizie wykorzystujemy klasyczną regresję harmoniczną (Fouriera) z dodatkowymi regresorami (czynnikami) i błędami autoregresji. W tym przypadku sezonowość wielokrotna modelowana jest za pomocą szeregów Fouriera o różnych okresach, czyli odpowiednich kombinacji funkcji sinus i cosinus (zwanych składowymi harmonicznymi). Dodatkowo do modelu można łatwo włączyć czynniki zewnętrzne (np. temperaturę, prędkość wiatru itp.). Krótkoterminowa korelacja czasowa modelowana jest za pomocą znanych modeli autoragresji. Dla uproszczenia, czynniki opóźnione nie zostały uwzględnione w modelu końcowym.
3.4.3 Modelowanie złożonej sezonowości za pomocą regresji harmonicznej
Rysunek 6 przedstawia komponenty sezonowości uzyskane na podstawie modelu regresji harmonicznej. Dotyczy to zarówno sezonowości dziennej, tygodniowej, jak i rocznej.
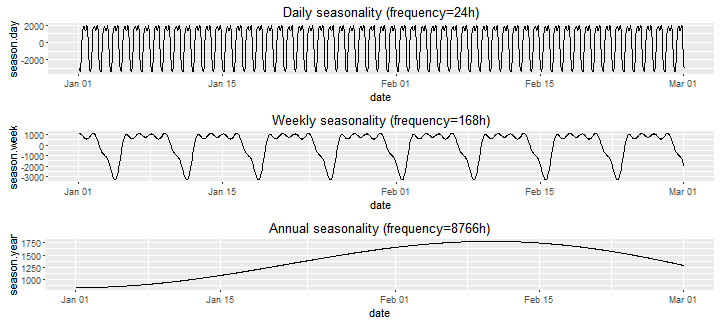 Rysunek 6. Składowe sezonowości w danych o obciążeniu energetycznym uzyskane na podstawie modelu regresji harmonicznej.
Rysunek 6. Składowe sezonowości w danych o obciążeniu energetycznym uzyskane na podstawie modelu regresji harmonicznej.
Dla celów poglądowych na rysunku 7 przedstawiono również oszacowane składowe harmoniczne (Fouriera), których kombinacja liniowa jest wykorzystywana do uchwycenia sezonowości rocznej w dopasowanym modelu. Zauważmy, że pokazanych jest pięć par składników harmonicznych, a liczba ta może być dalej optymalizowana w celu poprawy dokładności prognozy. Oczywiście, analogiczne składowe harmoniczne uzyskano dla sezonowości tygodniowej i dziennej (wyniki nie pokazane).
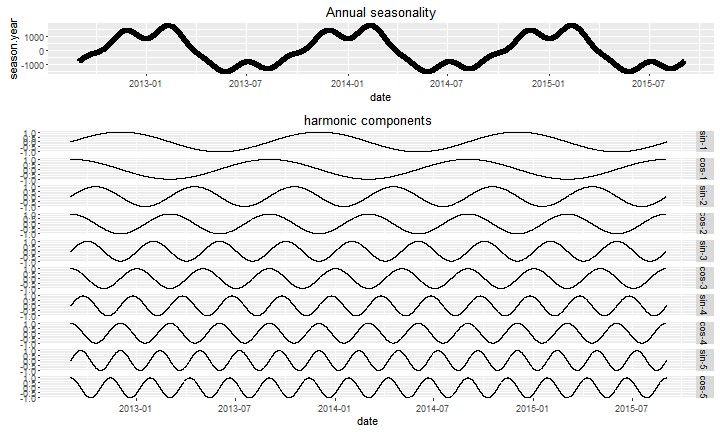 Rysunek 7. Składowe harmoniczne dla sezonowości rocznej.
Rysunek 7. Składowe harmoniczne dla sezonowości rocznej.
3.5 Głębokie sieci neuronowe
3.5.1 Idea
Głębokie uczenie (ang. deep learning) jest gałęzią uczenia maszynowego, która rozpatruje klasę modeli, których idea oparta jest na naśladowaniu biologicznych sieci neuronowych. Dzięki algorytmowi wstecznej propagacji błędów, dostępności sprzętu umożliwiającego równoległe obliczenia procesów o dużej złożoności w postaci procesorów graficznych oraz upowszechnieniu się dużych zbiorów danych, głębokie uczenie stało się ostatnio dość popularne.
Głębokie uczenie obejmuje szereg modeli przydatnych do wielu zadań związanych z identyfikacją, takich jak rozpoznawanie obiektów graficznych czy przetwarzanie języka naturalnego, a także analiza bardziej abstrakcyjnych pojęć, takich jak szeregi czasowe. Modele te są łatwe do skalowania, dają możliwość pełnego wykorzystania potencjału predykcyjnego dużych zbiorów danych. Ostatnie przełomowe odkrycia skłoniły wiele dużych firm technologicznych do opublikowania bibliotek open-source dedykowanych głębokiemu uczeniu.
Wadą modeli głębokiego uczenia jest mała interpretowalność spowodowana dużą liczbą parametrów, złożoności i brakiem oparcia na matematycznej teorii. Co więcej, modele te są niezwykle łatwe do przeuczenia, przez co nie nadają się do stosowania w przypadku małych zbiorów danych. Dodatkową przeszkodą jest to, że metody te są często bardzo złożone obliczeniowo, a zapewnienie odpowiedniej wydajności wymaga użycia drogiego sprzętu.
3.5.2 Co wybraliśmy?
Zbudowaliśmy standardową sieć typu feed-forward, która uczy się mapowania daty, czasu, zapotrzebowania na moc i warunków pogodowych w pojedynczym okresie godzinowym na zapotrzebowanie na moc w następnej godzinie. Ogólna struktura jest pokazana na rysunku 8.
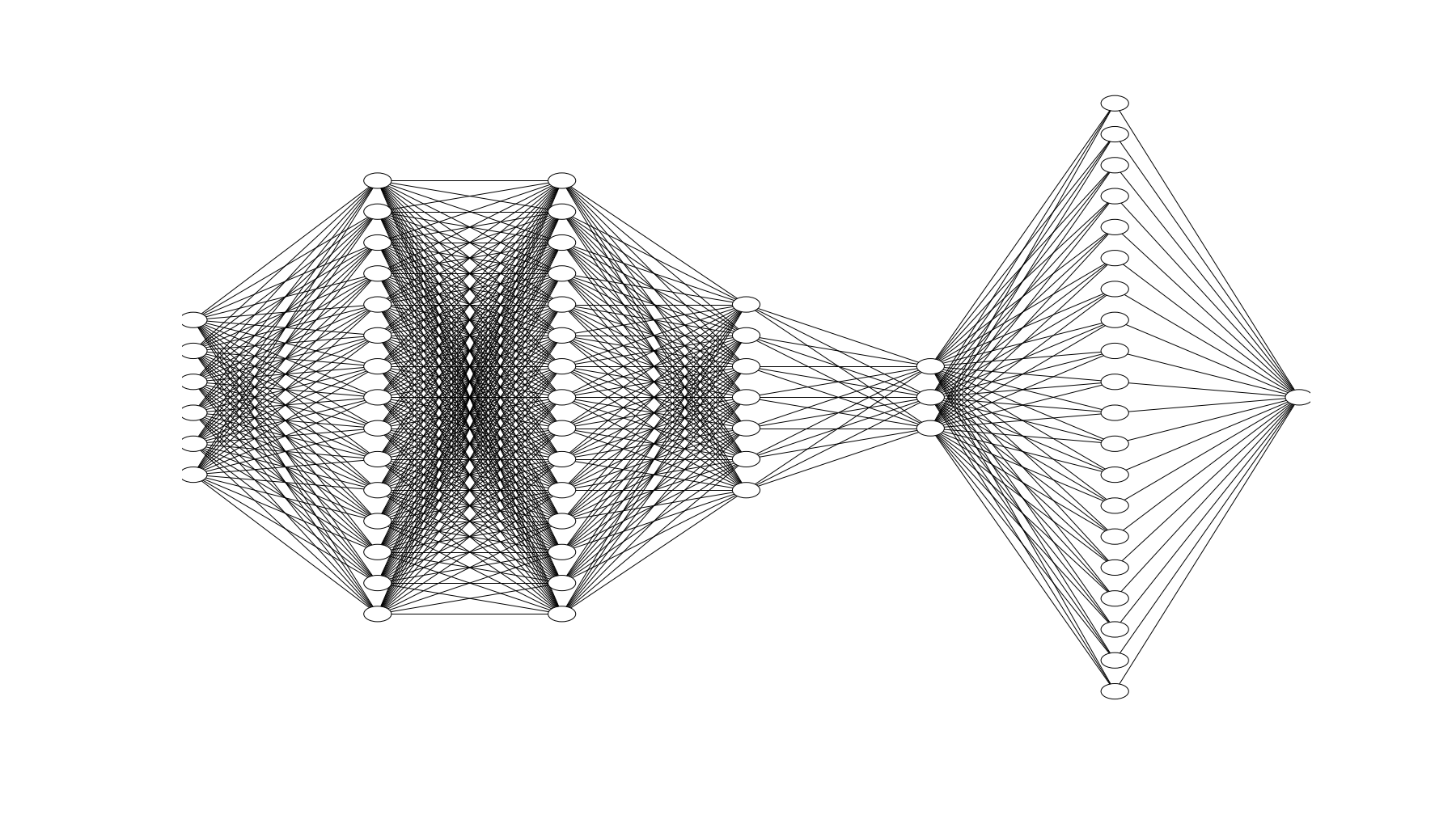 rysunek 8. Struktura sieci neuronowej.
rysunek 8. Struktura sieci neuronowej.
Warstwa wejściowa przyjmuje wektor 112 wartości wejściowych, gdzie miesiąc, dzień miesiąca, dzień tygodnia, godzina i dane pogodowe zostały przekazane jako zmienne dummy. Warstwa wejściowa przekazuje dane do stosu czterech w pełni połączonych warstw ukrytych składających się z 256, 256, 64 i 16 neuronów każda. Każda z tych warstw wykorzystuje metodę aktywacji tanh oraz dropout. Kolejna warstwa składa się z 817 neuronów z metodą aktywacji softmax. Warstwa ta koduje rozkład prawdopodobieństwa wartości przewidywanej. Każdy neuron w tej warstwie reprezentuje przekonanie, że zapotrzebowanie na moc na najbliższą godzinę będzie się mieściło w określonym przedziale o długości 20 MW. Aby wprowadzić procedurę optymalizacji do tej reprezentacji, do warstwy tej został dołączony pojedynczy neuron wyjściowy o stałych wagach, który oblicza wartość oczekiwaną rozkładu prawdopodobieństwa. Pełna sieć wykorzystuje 126,097 parametrów modelu we wszystkich warstwach.
Do trenowania modelu użyto algorytmu Stochastic Gradient Descent z momentem Nesterova, z średnim błędem względnym predykcji pojedynczego neuronu wyjściowego jako miarą błędu. Trening został przerwany po 1000 iteracji bez poprawy miary błędu na zbiorze danych walidacyjnych.
3.6 Agregacja prognoz
3.6.1 Idea
Ensemble learning jest z powodzeniem stosowany w statystyce i uczeniu maszynowym już od kilku dekad (patrz np. Hastie, Tibshirani i Friedman (2009)). Z grubsza rzecz biorąc, główną ideą takiego podejścia jest łączenie (agregowanie) wyników z wielu algorytmów uczących w celu uzyskania jeszcze lepszej wydajności predykcyjnej. Znaczne zróżnicowanie wśród modeli (członków komitetu) daje zazwyczaj lepsze wyniki.
Podobna procedura może być zastosowana również w kontekście prognozowania danych zależnych od czasu. Można się spodziewać, że łączenie prognoz będzie skutkowało lepszymi wynikami niż użycie pojedynczego modelu. Oczywiście istnieją różne schematy uśredniania, w tym: proste uśrednianie, uśrednianie ważone (wagi przypisane poszczególnym prognozom w zależności od ich dokładności), jak również różne warianty modeli regresyjnych (poszczególne prognozy są używane jako regresory).
3.6.2 Co wybraliśmy?
W naszej analizie zastosowany został prosty schemat uśredniania, czyli najbardziej naturalne podejście do łączenia prognoz uzyskanych z trzech różnych modeli. Obliczono średnią arytmetyczną wszystkich prognoz uzyskanych z poszczególnych modeli. Należy zauważyć, że pomimo swojej prostoty takie podejście jest bardzo solidne i szeroko stosowane w prognozowaniu biznesowym i ekonomicznym.
4 Wyniki
4.1 Błędy predykcji (walidacja na danych historycznych)
W kontekście prognozowania energii, powszechne jest rozważanie prognoz krótko-, średnio- lub długoterminowych (patrz np. Weron (2006)). W literaturze nie ma jednak zgoności co do tego, jakie rzeczywiste zakresy horyzontów prognozy stanowią każdą z tych klas prognoz, stąd rozstrzygnięcie pozostaje zależne od rozważanego problemu.
W celu dokładnego zbadania wydajności wszystkich modeli zdecydowaliśmy się na porównanie prognoz godzinowych dla trzech horyzontów: 60, 120 i 360 dni (każdy dzień odpowiada 24 punktom czasowym). Warto zaznaczyć, że prognozy godzinowe są konstruowane raczej dla krótszych horyzontów czasowych. W przypadku prognoz długoterminowych, można wykorzystać dane o niższej częstotliwości (np. dzienne zamiast godzinowych). Użyliśmy standardowego wskaźnika MAPE (średni błąd względny, ang. Mean Absolute Percentage Error) jako miary dokładności prognozy na zbiorze testowym (niewykorzystnym do uczenia modelu). Oczywiście, w zależności od celu biznesowego itp., mogą być użyte inne miary oceniające jakość predykcji.
Tabela 1 zawiera błędy prognozy MAPE uzyskane dla wszystkich rozważanych w naszej analizie podejść, tj. modelu szeregu czasowego, regresji, głębokiej sieci neuronowej oraz średniej prostej z tych trzech prognoz. Dodatkowo, jako wynik referencyjny posłużyły prognozy uzyskane na podstawie sezonowej metody naiwnej, tzn. wartości obciążenia energią z ostatniej doby są wykorzystywane jako prognozy na kolejne okresy (dni). Stosowanie metod naiwnych jako wzorców w prognozowaniu jest ważne. Dane o zapotrzebowaniu na energię często charakteryzują się wysokim poziomem średniej wielkości i stosunkowo niewielką skalą zmian sezonowych. Przy zachodzeniu takich własności, prognozy naiwne mogą wypadać zaskakująco dobrze. Oczywiście, użyteczność tych prognoz nie jest zbyt wysoka.
4.2 Historia i trzy prognozy
Figure 9 shows three time series. Each of them consists of historical energy load values followed by forecasts obtained from a particular method.
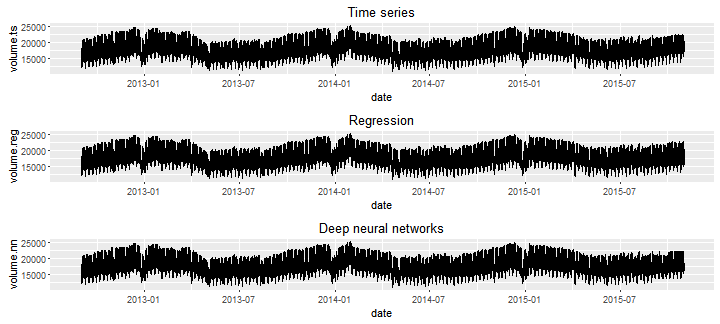 Rysunek 9. Dane historyczne i prognozy - porównanie wyników.
Rysunek 9. Dane historyczne i prognozy - porównanie wyników.
Celowo pozostawiliśmy granicę pomiędzy historią a prognozą niezaznaczoną. Dzięki temu widzimy, że wszystkie metody są w stanie odzwierciedlić sezonowość w prognozach. Ogólnie rzecz biorąc, wszystkie prognozy dają sensowne wyniki.
4.3 Bardziej szczegółowe porównanie prognoz
Rysunek 10 pozwala nam na bardziej szczegółowe porównanie wszystkich podejść do prognoz.
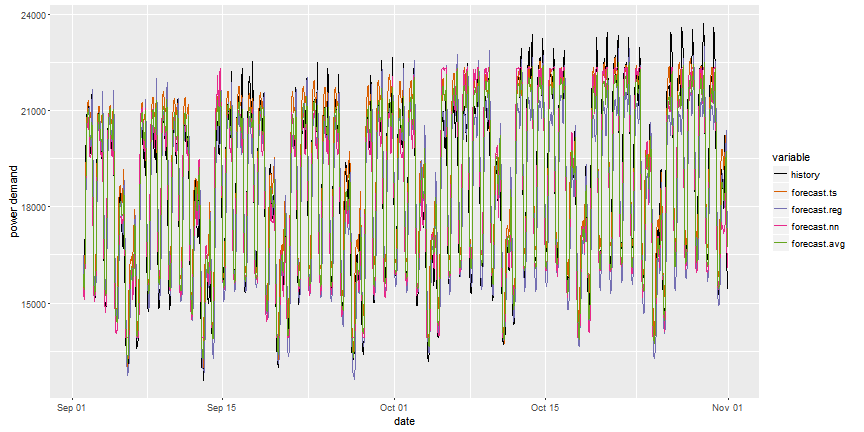 Rysunek 10. Porównanie prognoz dla wszystkich metod.
Rysunek 10. Porównanie prognoz dla wszystkich metod.
Rysunek 11 pokazuje szczegółowe porównanie prognoz dla wybranego tygodnia. Widać wyraźnie, że żadna z metod nie była w stanie przewidzieć spadku wolumenu w dniu 11. listopada, który jest świętem narodowym w Polsce.
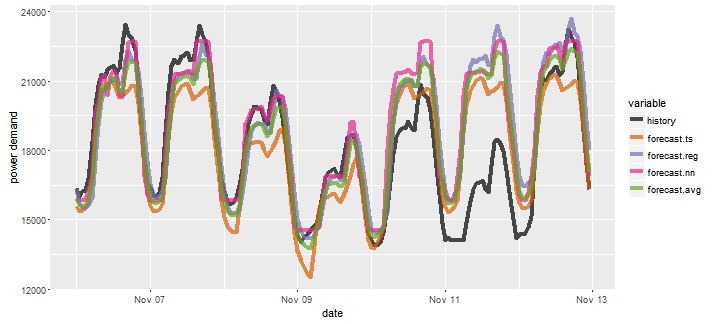 Rysunek 11. Porównanie prognoz dla wybranego tygodnia.
Rysunek 11. Porównanie prognoz dla wybranego tygodnia.
Widzimy, że istnieją znaczne różnice pomiędzy prognozami, np. że niektóre metody systematycznie zaniżają, a niektóre zawyżają. Takie zachowanie modeli można skorygować stosując niestandardowe kryteria błędu, np. uwzględniając koszty zawyżonej lub zaniżonej prognozy.
4.4 Aproksymacja gęstości rozkładu z wykorzystaniem sieci neuronowych
W przedostatniej warstwie naszego modelu głębokiego uczenia podjęta została próba wyznaczenia rozkładu prawdopodobieństwa wartości wyjściowych. Rysunek 12 przedstawia przykładowe wartości podane przez sieć do tej warstwy dla dwóch punktów danych. Obserwujemy, że o ile czasami sieć ma silne przekonanie co do niewielkiego zakresu wartości, to zdarzają się również przypadki, gdy spory zakres wartości odznacza się znaczącym prawdopodobieństwem.
Dostęp do szczegółowego rozkładu prawdopodobieństwa predykcji jest przydatny, w celu konstrukcji kontraktu bilansującego możliwe zyski i straty.
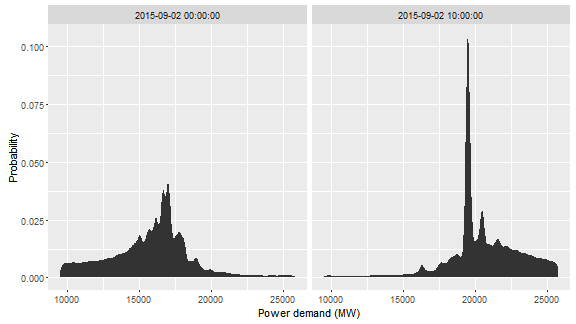 Rysunek 12. Aproksymacja gęstości prawdopodobieństwa za pomocą sieci neuronowej.
Rysunek 12. Aproksymacja gęstości prawdopodobieństwa za pomocą sieci neuronowej.
5 Użyte narzędzia
5.1 Raporty SYNOP
Dane pogodowe zostały pobrane z OGIMET, darmowego serwisu informacyjnego o pogodzie. Dane dostarczane są w postaci raportów SYNOP. Parsowanie danych SYNOP jest zadaniem nietrywialnym: format nie jest jednym z powszechnie używanych. Jest to format tekstowy, w którym informacje zakodowane są w liczbach, których semantyka określona jest zarówno przez wartość liczbową jak i pozycję. Co więcej, niektóre raporty nie są zgodne z żadną dokumentacją, którą udało nam się znaleźć, prawdopodobnie zawierają błędy w transkrypcji.
OGIMET zawiera dane począwszy od roku 2000. Polska objęta jest 82 stacjami. Dane z każdej stacji zawierają brakujące wartości. Brakujące wartości dotyczą okresów rzędów zarówno kilku godzin jak również lat. Dane zazwyczaj zawierają rekordy w godzinnych odstępach, jednak zdarzają się rekordy odbiegające od tego schematu.
Raporty SYNOP dla Polski zostały pobrane przy użyciu skryptu w języku Python, który uwzględnił różne ograniczenia usługi OGIMET API, w tym ścisłe limity na częstotliwość i rozmiar zapytań. Raporty zostały sparsowane i przekształcone w ramkę danych przy użyciu GNU text utils. Dalsze przetwarzanie wstępne zostało wykonane w R przy użyciu pakietu dplyr. Dla uproszczenia, odrzuciliśmy 500 rekordów, które nie zawierały informacji o godzinie. Dane dla każdej godziny były agregowane przez wszystkie stacje, które raportowały w danym okresie godzinowym. Szeregi czasowe danych pogodowych musiały być dopasowane do historycznych szeregów danych o zapotrzebowaniu na moc.
5.2 Regresja
Wykorzystano środowisko statystyczne R zasilane przez doskonały pakiet caret. Aby wybrać spośród wielu możliwych parametrów zastosowaliśmy hiperparametryzację po siatce parametrów z walidacją krzyżową.
Zadanie estymacji i oceny modeli może być zasobochłonne. Istotnym czynnikiem umożliwiającym zakończenie przetwarzania w rozsądnym czasie było zastosowanie procesów równoległych. Dodatkowo, wykonanie analizy wymagało zastosowania pewnych sztuczek przyspieszających obliczenia.
5.3 Modele szeregów czasowych
W celu dopasowania modeli szeregów czasowych wykorzystano środowisko statystyczne R oraz niektóre narzędzia dostępne w pakiecie (bibliotece) seminal forecast. Biorąc pod uwagę rozmiar danych, przy szukaniu najlepszy model ARMA konieczne było zmniejszenie obciążenia obliczeniowego, poprzez zastosowanie pewnego wbudowanego przetwarzania równoległego. Oryginalne dane zostały tylko nieznacznie przetworzone przed właściwym dopasowaniem modelu, tj. temperatura została przekształcona za pomocą klasycznej transformaty wielomianowej w celu obsługi zależności nieliniowych.
5.4 Głębokie sieci neuronowe
Algorytmy głębokiego uczenia zostały uruchomione na karcie graficznej NVIDIA GeForce GTX 960. Model został zdefiniowany w języku Python, przy użyciu biblioteki głębokiego uczenia Keras z backendem Theano. Dodatkowe przetwarzanie wstępne zostało wykonane przy użyciu Jupytera i Pandas. Ostateczny model wymagał około godziny obliczeń do osiągnięcia zbieżności.
6 Podsumowanie
Na koniec przyszedł czas na podsumowanie uzyskanych przez nas wyników.
Po pierwsze, staraliśmy się pokazać, że podobnie jak w przypadku innych zadań analitycznych, prognozowanie obciążenia energią elektryczną może być realizowane na wiele sposobów z uzyskaniem lepszych i gorszych rezultatów. Oczywiście wybór optymalnego podejścia zależy od celu biznesowego, oczekiwań, a także od doświadczenia analityka danych. Z jednej strony nie ma metod, które byłyby uniwersalne i optymalne dla wszystkich zastosowań; prognozowanie zapotrzebowania na energię jest właśnie jednym z przykładów sytuacji, kiedy nie można dokonać jednoznacznie najlepszego wyboru. Z drugiej strony, często nie trzeba stosować wyrafinowanych metod, aby uzyskać satysfakcjonujące rezultaty.
Jak można było się spodziewać, wszystkie zaawansowane podejścia równomiernie (tj. dla wszystkich rozważanych horyzontów prognozy) przewyższają prostą sezonową metodę naiwną, która została użyta jako procedura referencyjna. Ogólnie najlepsze wyniki uzyskano dla modeli głębokich sieci neuronowych, które są najbardziej elastycznym podejściem uwzględnionym w naszym badaniu. Jednak ich istotnym ograniczeniem może być brak możliwości interpretacji, a także obciążenie obliczeniowe wymagane do uczenia końcowej sieci.
Efektywność danego podejścia prognostycznego zależy zazwyczaj od wielu czynników, w tym regularności lub nieregularności wzorców zapotrzebowania na energię, obecności czasowych zmian związanych ze świętami lub warunkami pogodowymi w danym okresie czasu, itp. Dlatego zawsze zaleca się dokładną ocenę wydajności danego algorytmu prognostycznego poprzez testowanie na danych historycznych.
Prosta agregacja (lub uśrednianie) prognoz uzyskanych na podstawie różnych procedur może, ale nie musi, dać lepszą dokładność. Na pewno jest warta rozważenia w przypadku zastosowania kilku różnych procedur prognostycznych.
Wszystkie te prognozy w tych trzech strukturach mogą być poprawione, np. poprzez użycie bardziej wyrafinowanych zmiennych opisujących czynniki, zmianę głębokości danych historycznych (okna), które używamy do prognozowania, użycie innych metod lub bardziej staranny dobór parametrów.
Można zastosować własne kryteria optymalizacji odzwierciedlające warunki umowy pomiędzy dostawcą a odbiorcą, np. większa kara za niedoszacowanie niż za przeszacowanie przyszłego wolumenu.
Pomimo że modele sieci neuronowych nie są interpretowalne, możliwe jest dostarczenie oszacowań opartych na gęstościach rozkładów prawdopodobieństwa. Problemem jest jednak zbieżność tych modeli.
Żadna z metod nie przewidziała niższego popytu podczas świąt narodowych o ustalonej dacie. Podczas gdy niektóre metody mogą nie być wystarczająco ekspresyjne, aby zapamiętać te wydarzenia, struktura modelu sieci neuronowej została zaprojektowana specjalnie po to, aby umożliwić sieci wyrażenie relacji niezbędnych do dostosowania przewidywań dla tych okresów.
Wreszcie, należy pamiętać, że minimalizacja błędu prognozy nie jest rozwiązaniem na wszystko! Istnieją inne ważne kwestie w praktycznym prognozowaniu, takie jak: interpretowalność modelu, kontrola ryzyka i stabilności modelu, posiadanie pełnej kontroli nad procesem prognozowania, ciągłe monitorowanie działania modelu itp.
Wybór najlepszych metod zależy od tych czynników, a nie tylko od błędu prognozy.
Zobacz również


Dług technologiczny w projektach data…
W projektach data science także występuje dług technologiczny.…
Dowiedz się więcej
Jaki jest jeden z najbardziej…
Bycie zadowolonym z rozwiązania niewłaściwego problemu jest zazwyczaj…
Dowiedz się więcej